

You've probably heard about machine learning (ML) and its impact on engineering, sciences, marketing, and frankly any field where data is involved. The nuts and bolts of machine learning application development might be unfamiliar. In this post, we will discuss the high-level steps involved in both developing and utilizing a machine learning application.
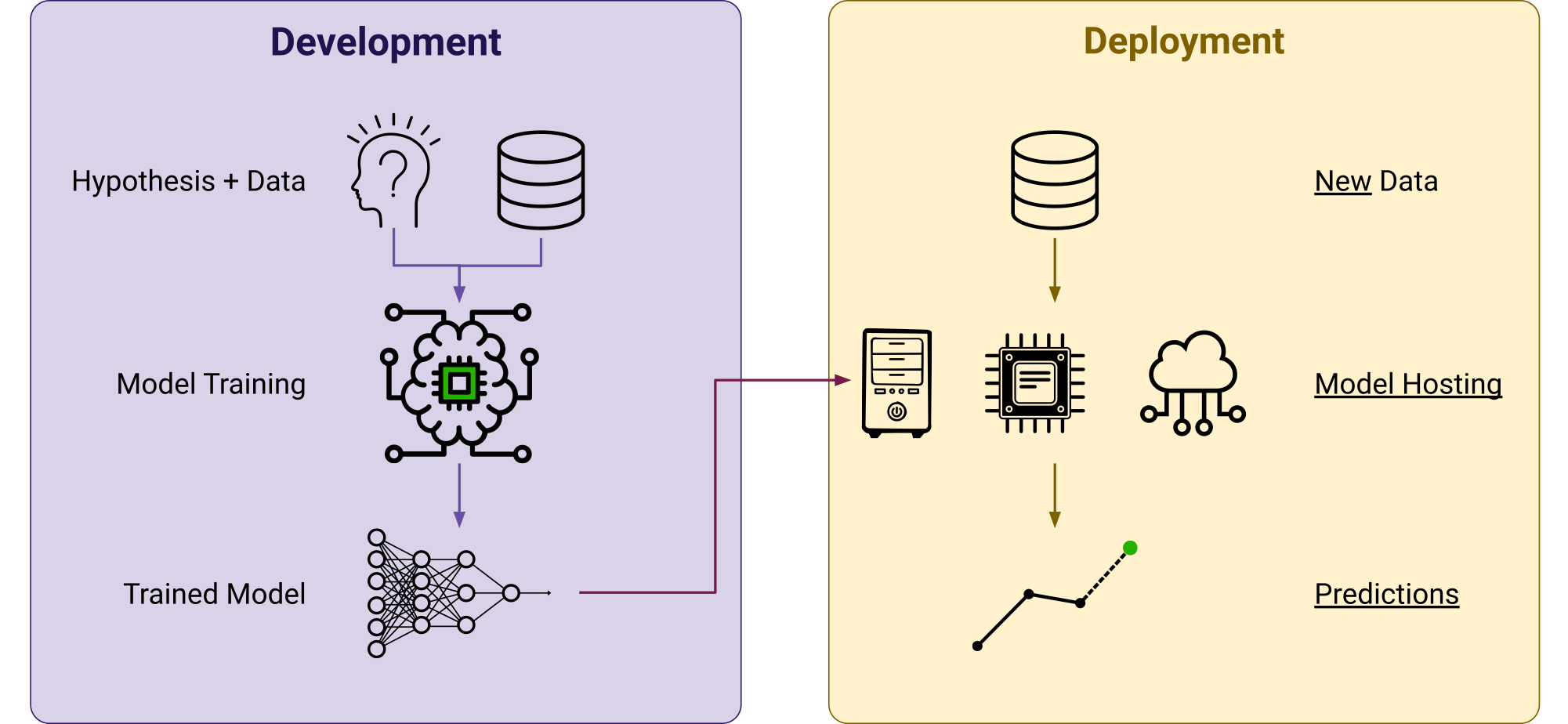
Utilizing an ML model usually involves two phases:
- Development: model is trained and evaluated
- Deployment: the trained model is setup for utilization
Although the boundary between these two phases has faded over time, most projects do have a development and deployment phase. Let's dig a bit deeper into the steps in each phase.
Development Phase
Hypothesis + Data
To get started, one needs both a dataset to work with and a hypothesis to explore. Here are a few examples:
- Given historical sales data, forecast the future sales
- Given historical sensor data from a process line, detect conditions that correlate with products failing the quality test
- Given a set of images with an object of interest, detect the location of the object
- Given a database of material descriptors and experimental properties, predict experimental properties for a new material from the descriptors
We notice right away that machine learning is tied to the availability of data. Without data, we cannot leverage machine learning.
Model Training
Next, we will use machine learning techniques to find a mathematical relationship between our inputs and the desired outcome. A linear curve fitting task exemplifies this step. The model assumed in this case is y = a*x + b, where the input is x and the desired outcome is y. Our goal is to find parameters a and b that can map our input x to output y.
Machine learning models are just more general. They have many more parameters that are trained by feeding them with data. But they too find mappings between inputs and outputs. This mapping is used to find abnormal patterns, forecast variables into the future, and much more.
In order to develop a model, certain steps are followed to make sure the model development is done properly. For example, the dataset is usually divided into 3 sets:
- Training: Used for training and obtaining model parameters
- Validation: Used for evaluating a model performance and tune as needed
- Test: Calculate final performance of a tuned model
Other steps include cleaning and normalizing the data and performing error analysis. We cover these steps and show how to develop a full machine learning model in our Getting Started with Machine Learning workshop.
Trained Model
The outcome of model training is a suitable model for the problem at hand. The model is basically a mathematical function with trained parameters. Back to our curve fitting example, this means that we know our output is a linear function of the input, and what the trained values of a and b are. So technically, we should be able to use this model and make predictions of our desired outcome from new inputs. The trained model now needs to be hosted somewhere that is accessible to the desired application. This is known as model deployment.
Deployment Phase
Model Hosting
Until this point the model has been available only on our machine. We can process new input data locally, from a csv file given to us for example. Basically this means the model is hosted on our local machine. Alternatively we can host it on the cloud or on an embedded processor in the field. By hosting a model, we set up the proper environment for the model to receive new data and make predictions.
New Data
The hosted model can now be passed new data. In this way we can generate predictions.
Predictions
Now is the time to see how our model is performing on a new input. If care was taken to follow the model training process properly during the development phase there, should be few surprises at this point. However, it may happen that new data brings a few unexpected findings.
For example, we might have assumed our input data always follow a certain format, but in practice it can slightly vary. Or our training data was from one condition (e.g. images from daytime) whereas new data is from another condition (e.g. low-light conditions). This may cause our model to perform poorly. If this happens, a proper analysis of the errors can be done and that information used to make updates to the model.
Conclusion
In this post, we covered the steps required to utilize machine learning models in practice. There is an iterative element to this whole process, cycling between development and deployment phases to answer new questions and improve model performance. But it all starts with a question or hypothesis and a set of data to explore with.